California Data Analyzing
Import the Libraries and Data Cleaning
drug_overdose = read_csv("./data/VSRR_Provisional_Drug_Overdose_Death_Counts.csv") %>%
janitor::clean_names()
state_level = c(state.name[1:8], "District of Columbia", state.name[9:32],"New York City", state.name[33:50])
drug_overdose_52 =
drug_overdose %>%
filter(!(state_name %in% c("United States"))) %>%
relocate(state_name) %>%
mutate(month = factor(month, levels = month.name), # change month and year to factor
year = factor(year),
state_name = factor(state_name, levels = state_level)) %>%
arrange(state_name) %>%
group_by(state_name, year) %>%
mutate(month = sort(month))
drug_overdose_death =
drug_overdose_52 %>%
select(-c(state, footnote_symbol, percent_complete, period, percent_pending_investigation, predicted_value)) %>%
filter(indicator %in% c("Number of Deaths", "Percent with drugs specified", "Number of Drug Overdose Deaths"))
drug_categories =
drug_overdose_52 %>%
ungroup() %>%
select(-c(state, footnote_symbol, percent_complete, period, percent_pending_investigation, footnote, predicted_value)) %>%
filter(str_detect(indicator, "T4"))By Drug Type
CA_death =
drug_overdose_52 %>%
filter(state_name %in% "California",
indicator %in% c("Number of Deaths", "Number of Drug Overdose Deaths")) %>%
select(year, month, indicator, deaths = data_value) %>%
pivot_wider(
names_from = indicator,
values_from = deaths
) %>%
janitor::clean_names() %>%
group_by(year, month) %>%
mutate(
percent_overdose_death = number_of_drug_overdose_deaths / number_of_deaths
) %>%
mutate(year = factor(year))
CA_df =
drug_categories %>%
filter(state_name %in% c("California"))
ggplot(CA_df, aes(indicator, data_value))+
geom_boxplot(aes(fill = indicator), alpha = 0.5) +
scale_x_discrete(labels = c("Psychostimulants \n with abuse potential \n (T43.6)", "Methadone \n (T40.3)", "Natural & \n semi-synthetic \n opioids \n (T40.2)", "Natural & semi-\n synthetic opioids, \n incl. methadone \n (T40.2, T40.3)", "Heroin \n (T40.1)", "Cocaine \n (T40.5)", "Synthetic opioids, \n excl. \n methadone \n (T40.4)", "Natural, \n semi-synthetic, & \n synthetic opioids, \n incl. methadone \n (T40.2-T40.4)", "Opioids \n (T40.0-T40.4,\n T40.6)")) +
guides(fill = guide_legend(nrow = 6, byrow = TRUE)) +
labs(
title = "CA Number of Drug Overdose Deaths with Drug Categories (2015 - 2021)",
x = "Drug Categories",
y = "Number of Drug Overdose Deaths",
caption = "Data comes from VSRR_Provisional_Drug_Overdose_Death_Counts dataset."
) 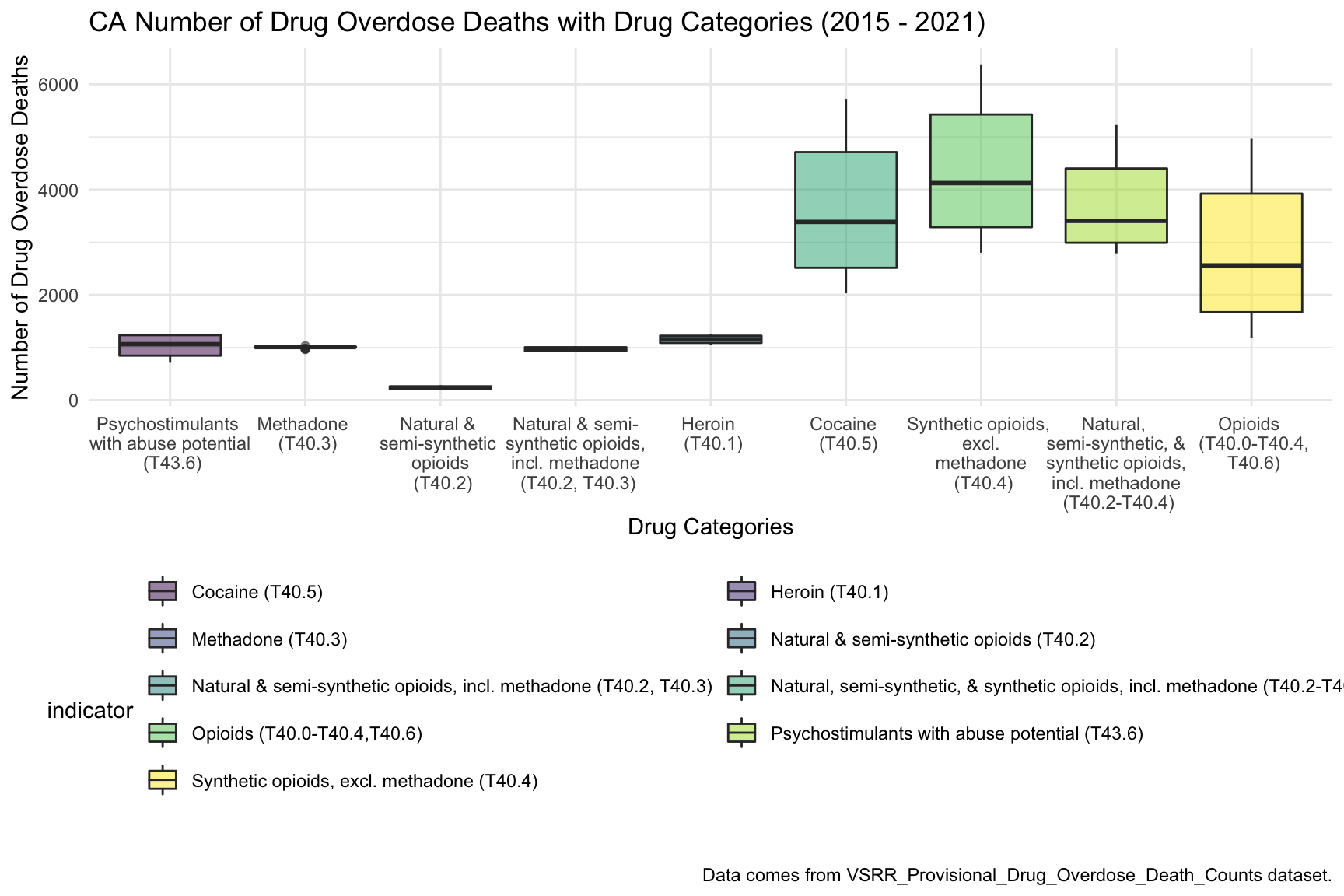
From this graph we can see that highest drug overdose death for California is caused by Synthetic opioids,methadone (T40.4). The following Drug Categories cause high overdose death are Cocaine and semi-synthetic opioids.
By Year
ca_death_by_year =
drug_overdose_52 %>%
filter(state_name %in% c("California")) %>%
ungroup() %>%
select(year, month, indicator, data_value) %>%
filter(indicator %in% c("Number of Deaths", "Number of Drug Overdose Deaths")) %>%
pivot_wider(
names_from = indicator,
values_from = data_value
) %>%
janitor::clean_names() %>%
group_by(year, month) %>%
mutate(
percent_overdose_death = number_of_drug_overdose_deaths / number_of_deaths
)
ca_death_by_year %>%
ungroup() %>%
ggplot(aes(x = month, y = percent_overdose_death, color = year)) +
geom_point() +
geom_line(aes(group = year)) +
labs(
title = "Percent of Drug Overdose Deaths over Total Number of Deaths by Year in CA",
x = "Months",
y = "Percent of Drug Overdose Deaths",
caption = "Data comes from VSRR_Provisional_Drug_Overdose_Death_Counts dataset from 2015 to 2021)."
)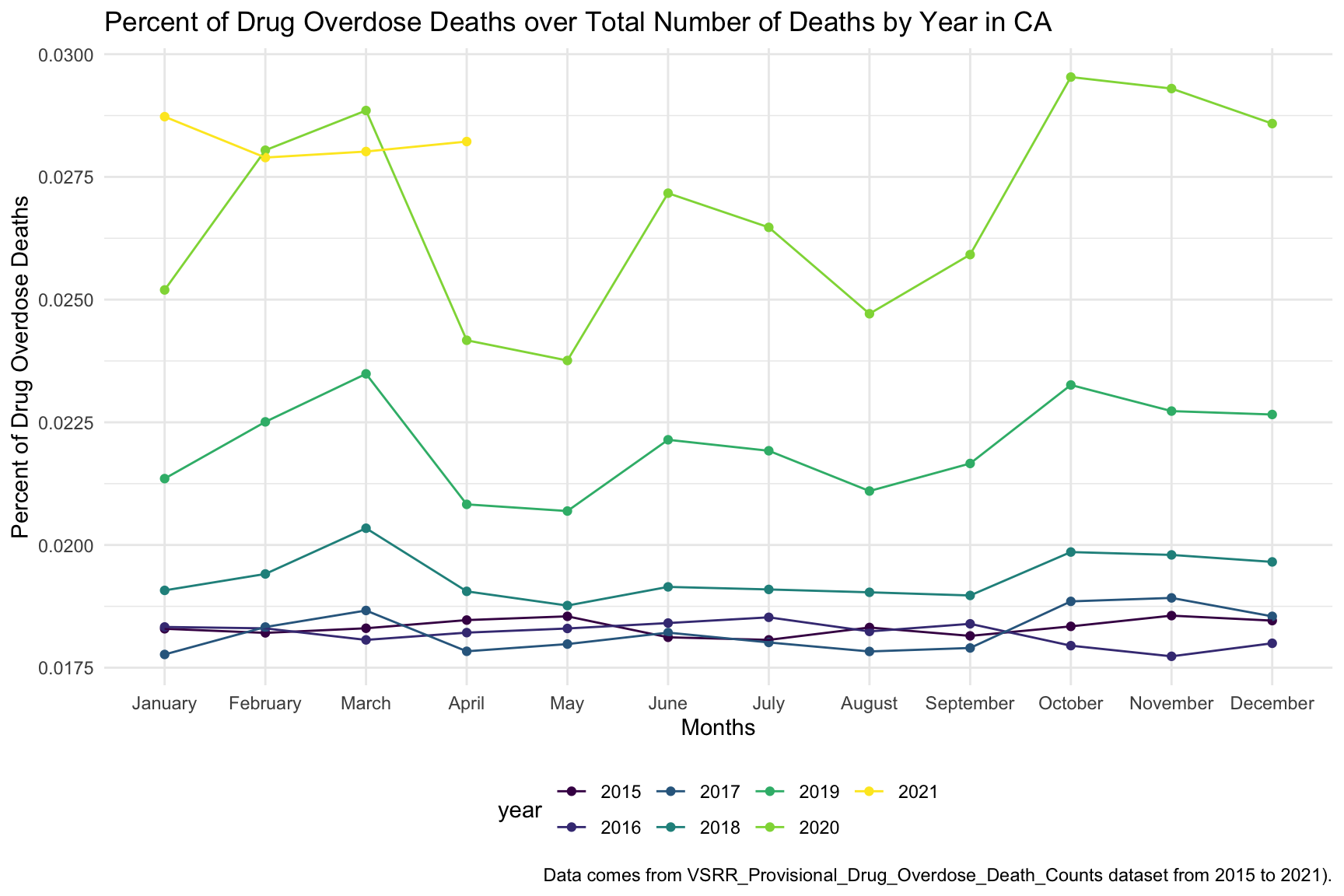
In the graph of Drug Overdose Deaths with Drug Categories by Year, I can observe that year 2020 have higher number of drug overdose death than other years, which can be cause by covid-19 and self-isolation.
ggplot(ca_death_by_year, aes(x = month, y = percent_overdose_death, group = year, color = year)) +
labs(title = "") +
geom_line() +
geom_point() +
facet_grid(.~year) +
labs(
title = "Percent of Number of Drug Overdose Deaths with Drug Categories by Year in CA",
x = "Month",
y = "Percent of Drug Overdose Deaths",
caption = "Data comes from VSRR_Provisional_Drug_Overdose_Death_Counts dataset between 2015 and 2021."
) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) 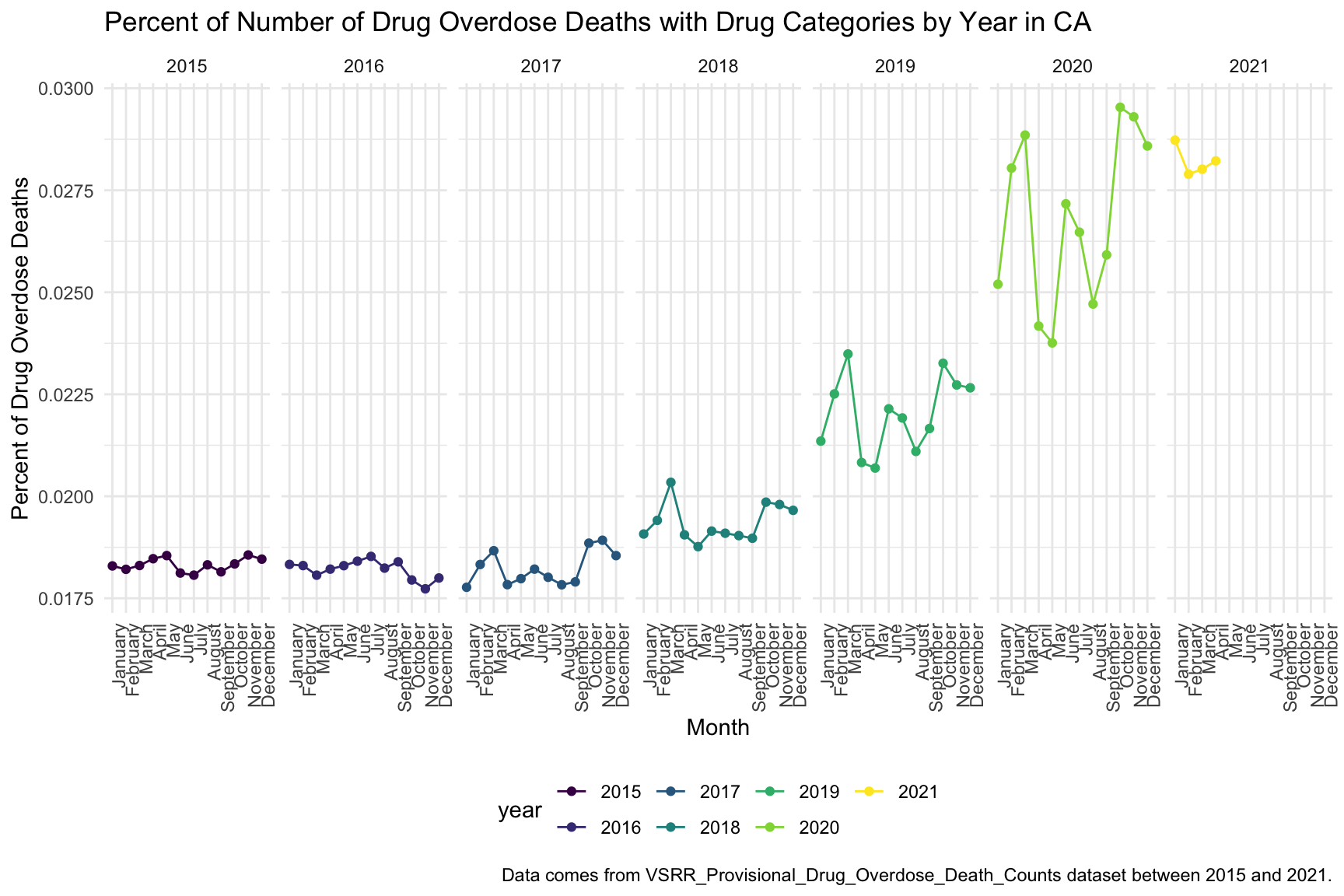
In the graph of Each month Drug Overdose Death Within a Year, we are able to see the increasing trend of drug overdose in continuous years. Cause by the COVID-19, there is large increase in number of drug overdose death.
Drug ~ Year
CA_df %>%
filter(year %in% (2019:2021)) %>%
ggplot(aes(x = year, y = data_value, color = indicator)) +
geom_smooth(aes(group = indicator), se = FALSE) +
guides(color = guide_legend(nrow = 6, byrow = TRUE)) +
labs(
title = "Number of Drug Overdose Deaths by Year in CA",
x = "Year",
y = "Number of Drug Overdose Deaths",
caption = "Data comes from VSRR_Provisional_Drug_Overdose_Death_Counts dataset between 2019 and 2021."
)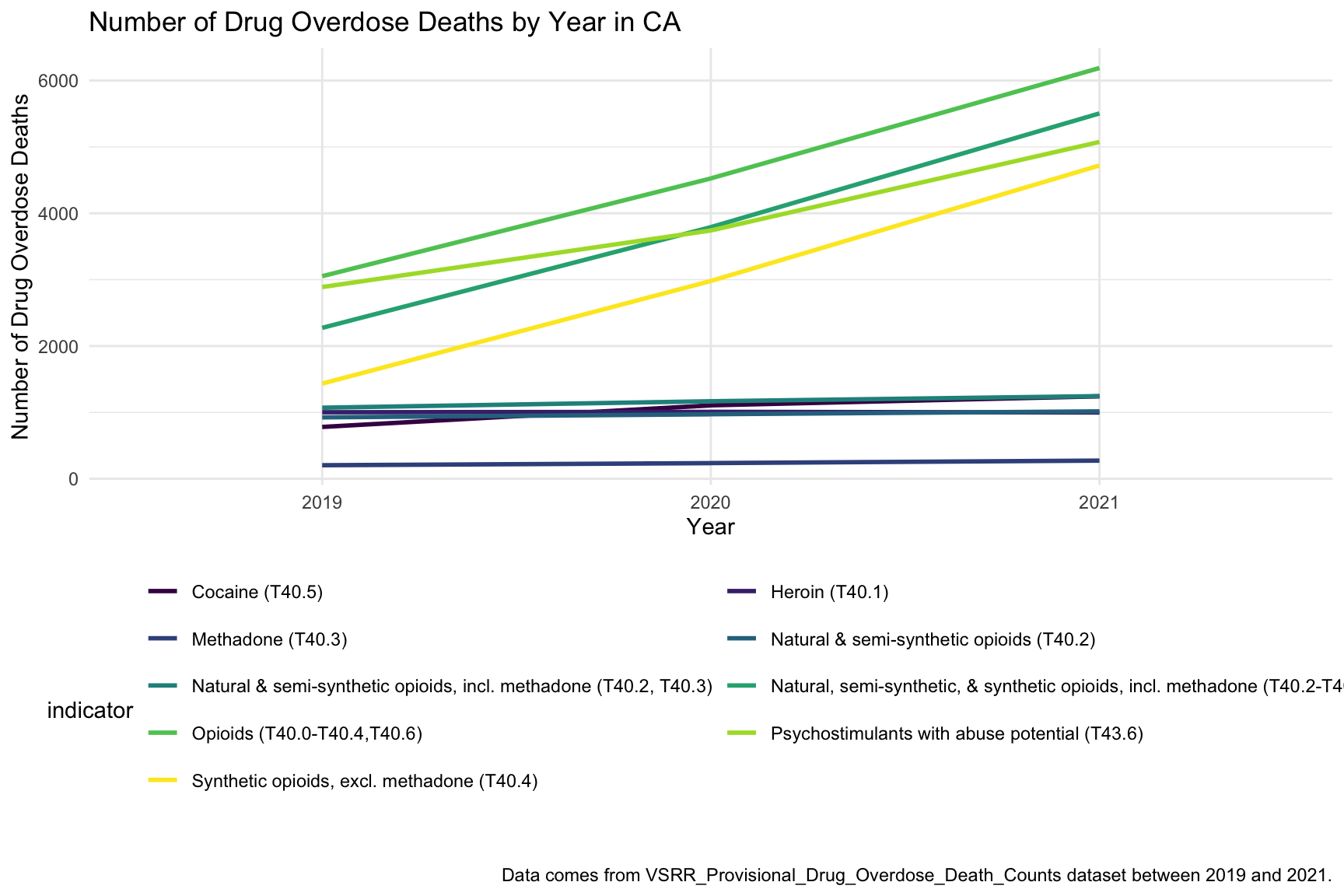
In the graph of Number of Drug Overdose Deaths with Drug Categories by Year, we can see that drug overdose death keep increasing over the years with almost all type of drug. Since we miss data from 2015-2018, so we just include 2019-2021 in this graph.
By Age and Race
ca_death_by_age =
read_csv("./data/agegroup_race_state_year_99-19.csv") %>%
janitor::clean_names() %>%
select(state, year, ten_year_age_groups, race, deaths, population) %>%
filter(state %in% c("California")) %>%
mutate(year = factor(year),
crude_rate = deaths/population * 100000)
ca_death_by_age %>%
mutate(ten_year_age_groups = gsub("years", "", ten_year_age_groups)) %>%
ggplot(aes(x = ten_year_age_groups , y = crude_rate, fill = race)) +
geom_boxplot(alpha = 0.5)+
labs(y = "Drug Overdose Death Crude Rates", x = "Age Groups")+
facet_grid(~race) +
labs(
title = "Number of Drug Overdose Deaths with Drug Categories by Age and Race in CA") +
theme(axis.text.x = element_text(angle = 90, vjust = 0.4, hjust = 1))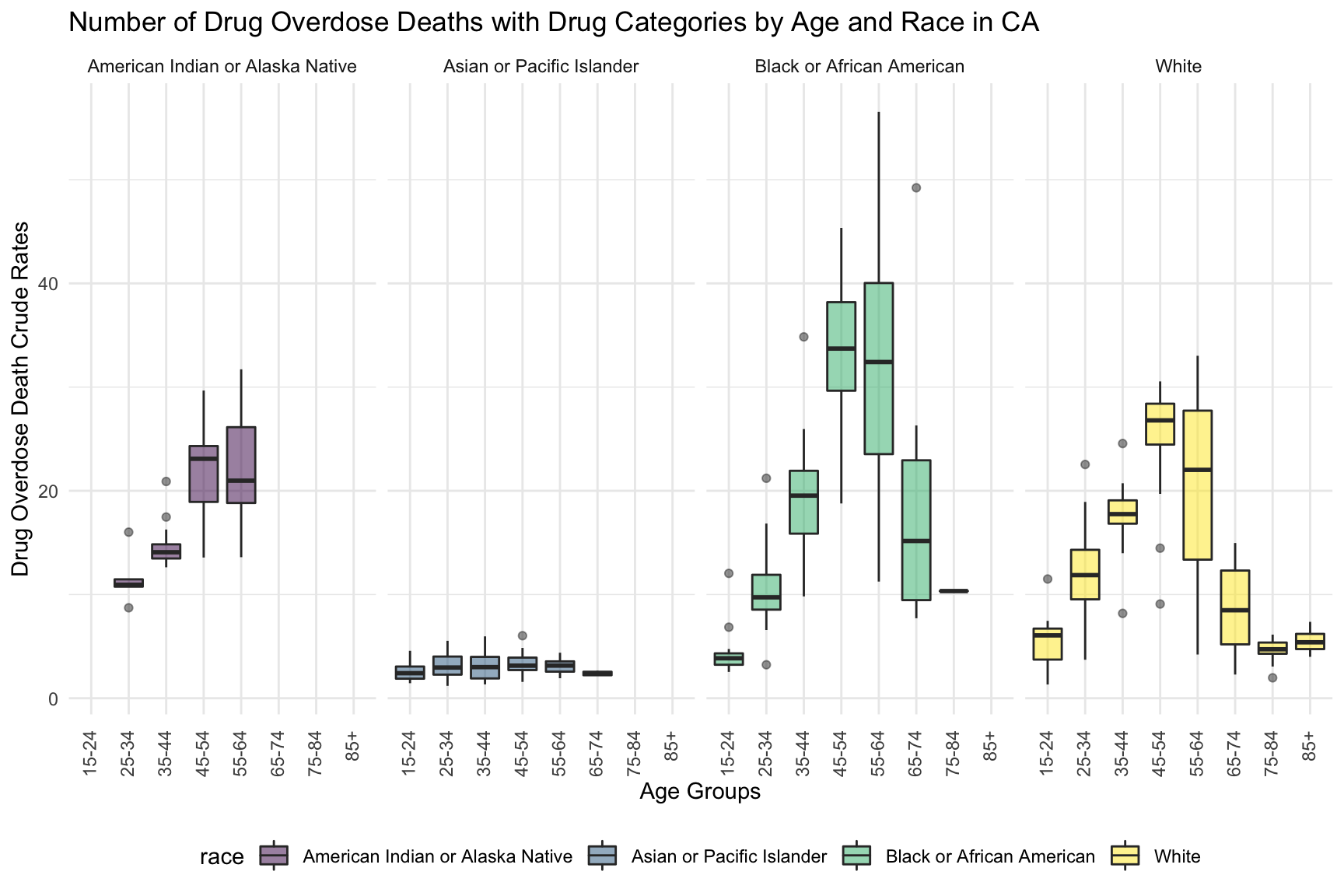
Overdose death with Drug Categories by Age and Race shows that people among age 55-64 across all races have highest death rate. Black or African Americans have highest death rate among all races.
Income
Number of death vs median household income
CA_income_df =
read_csv("./data/median_household_income_CA.csv") %>%
janitor::clean_names() %>%
select(year, household_income_by_race, household_income_by_race_moe, geography) %>%
filter(str_detect(geography,"CA|California|United States"),
year >= "2015") %>%
mutate(year = factor(year))
CA_income_df %>%
mutate(text_label = str_c("Year: ", year, "\nMedian Household Income: $", household_income_by_race,
"\nMargin of error: ± $", household_income_by_race_moe)) %>%
plot_ly(
x = ~year, y = ~household_income_by_race, color = ~geography, text = ~text_label,
alpha = 0.5, type = "scatter", mode = "markers+lines", colors = "viridis", error_y = ~list(array = household_income_by_race_moe)) %>%
layout(
title = "Median Household Income: CA vs. The U.S",
xaxis = list(title = "Year"),
yaxis = list(title = "Median Household Income"))From the graph Median Household Income: CA vs. The U.S, we can see that California have higher median household income then US and northern part of California have highest income compare other parts of California.
Income and drug overdose death percent by year
CAincome_drug_df =
CA_death %>%
ungroup() %>%
group_by(year) %>%
summarize(overdose_death_rate = sum(number_of_drug_overdose_deaths)/sum(number_of_deaths)) %>%
inner_join(., CA_income_df %>% filter(geography %in% "California"))
year_death =
CAincome_drug_df %>%
ggplot(aes(x = year, y = overdose_death_rate, group = NA))+
geom_point()+
geom_line()
income_year =
CAincome_drug_df %>%
ggplot(aes(x = year, y = household_income_by_race, group = NA))+
geom_point()+
geom_line()
income_year =
CAincome_drug_df %>%
ggplot(aes(x = year, y = household_income_by_race, group = NA))+
geom_point()+
geom_line()
smooth =
CAincome_drug_df %>%
ggplot(aes(x = household_income_by_race, y = overdose_death_rate, group = NA))+
geom_point() +
labs(y = "Drug Overdose Death Crude Rates", x = "Median Household Income") +
geom_smooth(method = "lm", se = FALSE, color = "royalblue4")
(year_death + income_year)/smooth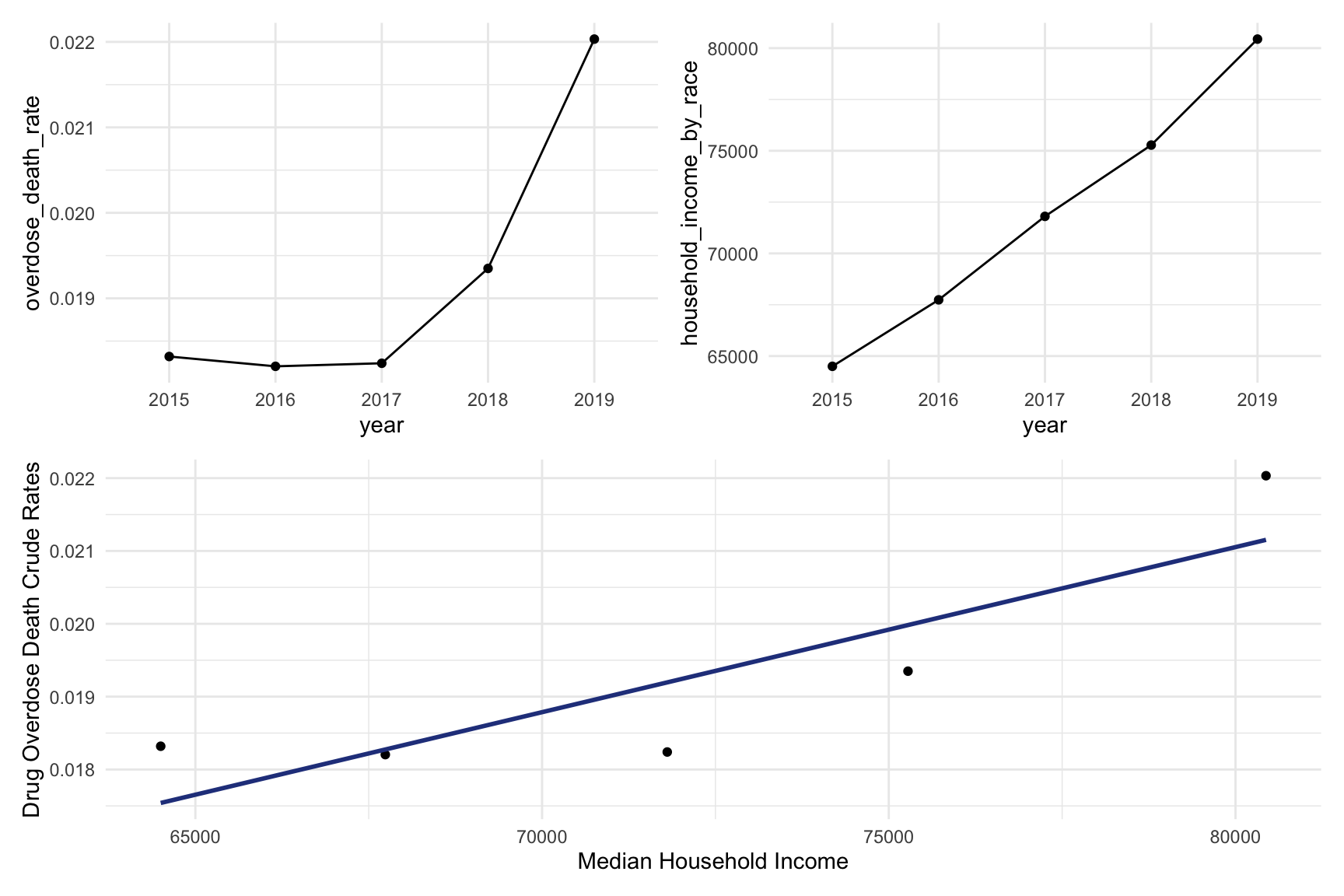
From graph income VS drug overdose we can find that higher drug overdose rate have association with higher income.
CA Drug Map
ca_county_df =
read_csv("./data/NCHS_-_Drug_Poisoning_Mortality_by_County__United_States.csv") %>%
janitor::clean_names() %>%
filter(state %in% "California") %>%
select(year, county, population, death_rate = model_based_death_rate) %>%
separate(county, into = c("county", "useless"), sep = " County") %>%
select(-useless) %>%
mutate(year = factor(year),
county = str_to_lower(county)) %>%
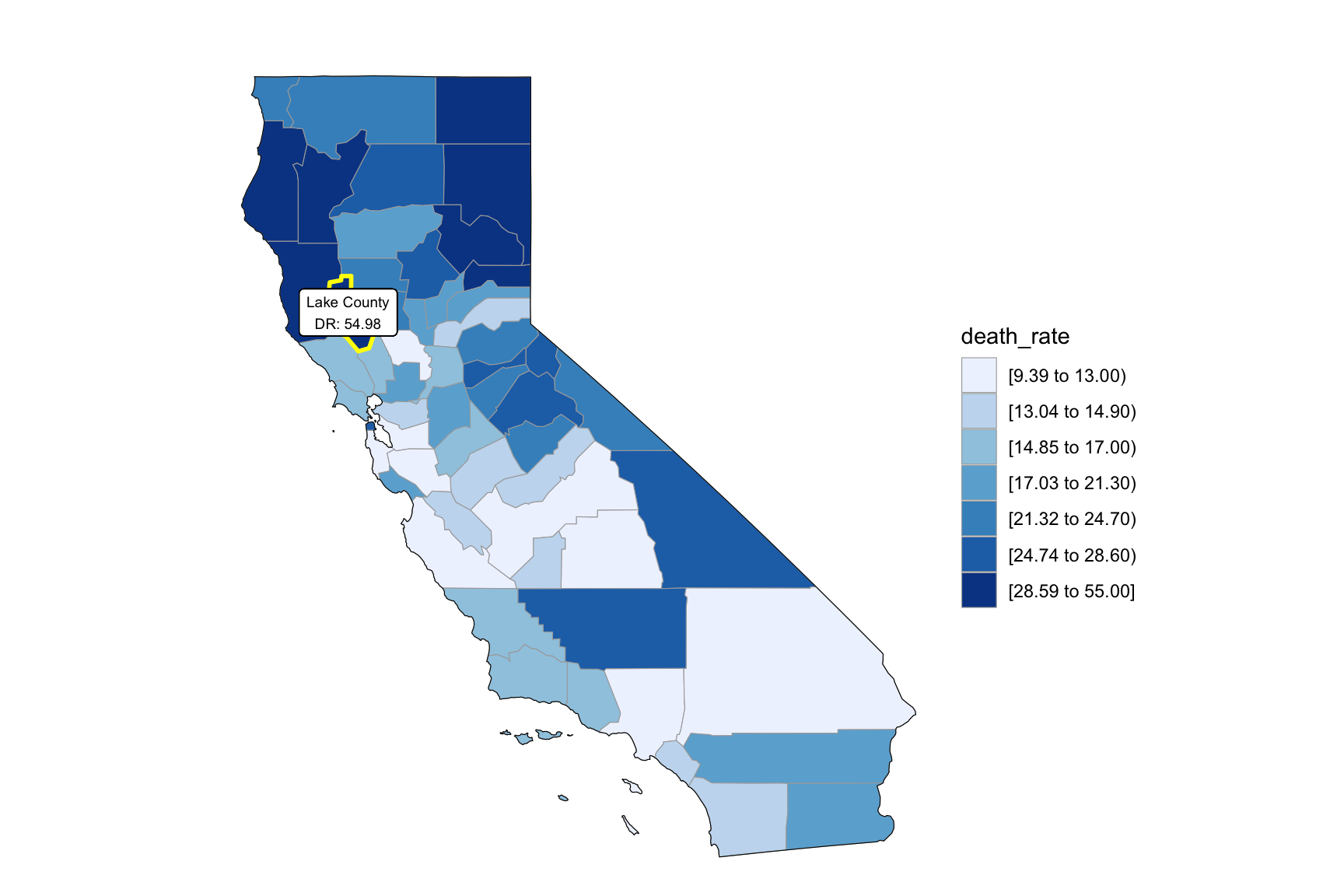
relocate(county)We can see that the highest death rate occur in north California across the years. From the income graph, north California have the highest income compare to other part of California. So we can find that higher drug overdose rate have association with higher income.
Counties change, 5-yr interval
2003
year_select = 2003
start_county_df = left_join(ca_county_df ,abc, by = "county") %>%
select(county, year, death_rate, fips) %>%
filter(year == year_select)
start_county_df %>%
group_by(fips) %>%
mutate(fips = as.numeric(fips)) %>%
rename(region = fips,
value = death_rate) %>%
county_choropleth(state_zoom = c("california"),
legend = "death_rate")+
highlight_county(start_county_df[which.max(pull(start_county_df, death_rate)),])+
add_text_county(start_county_df[which.max(pull(start_county_df, death_rate)),])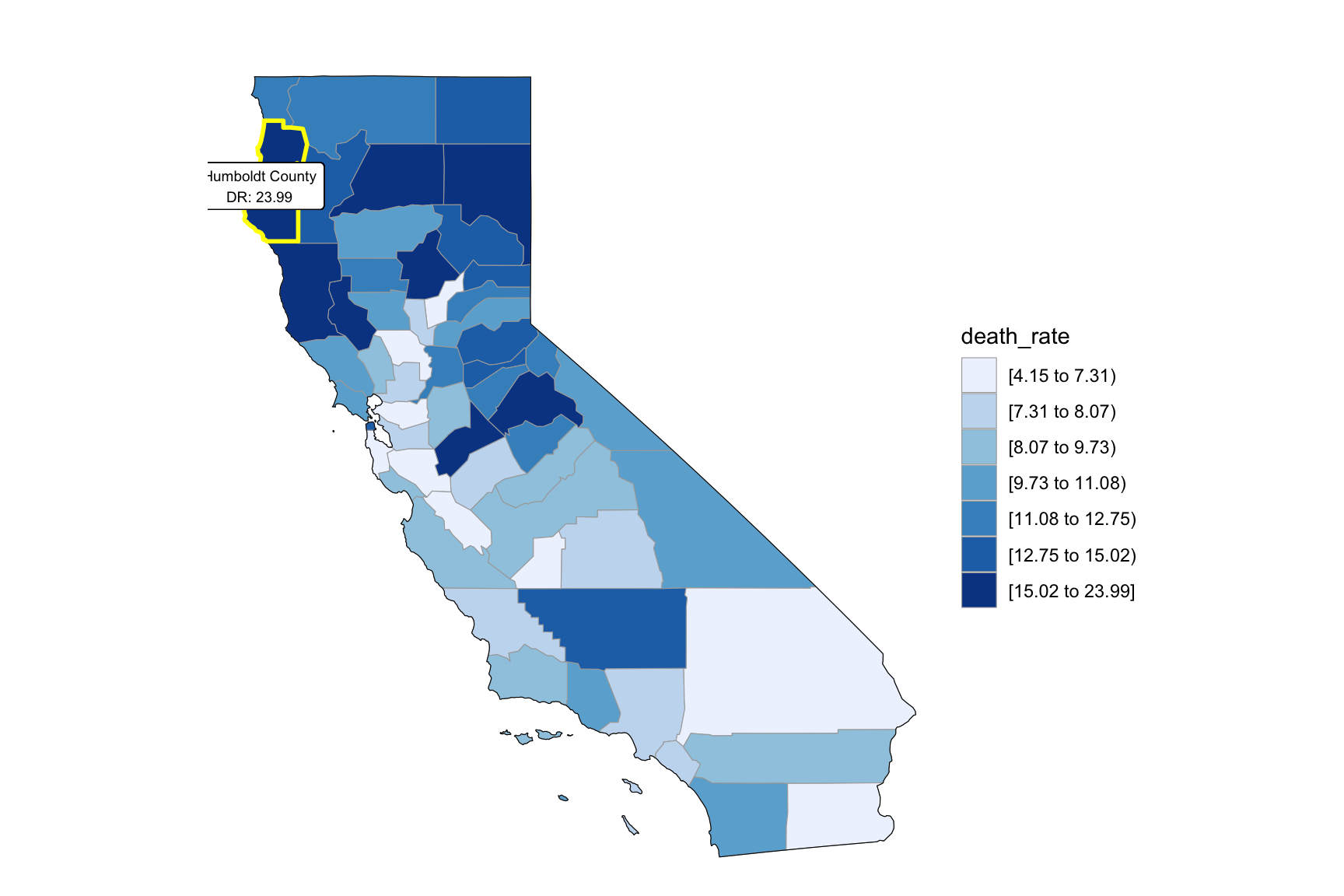
2008
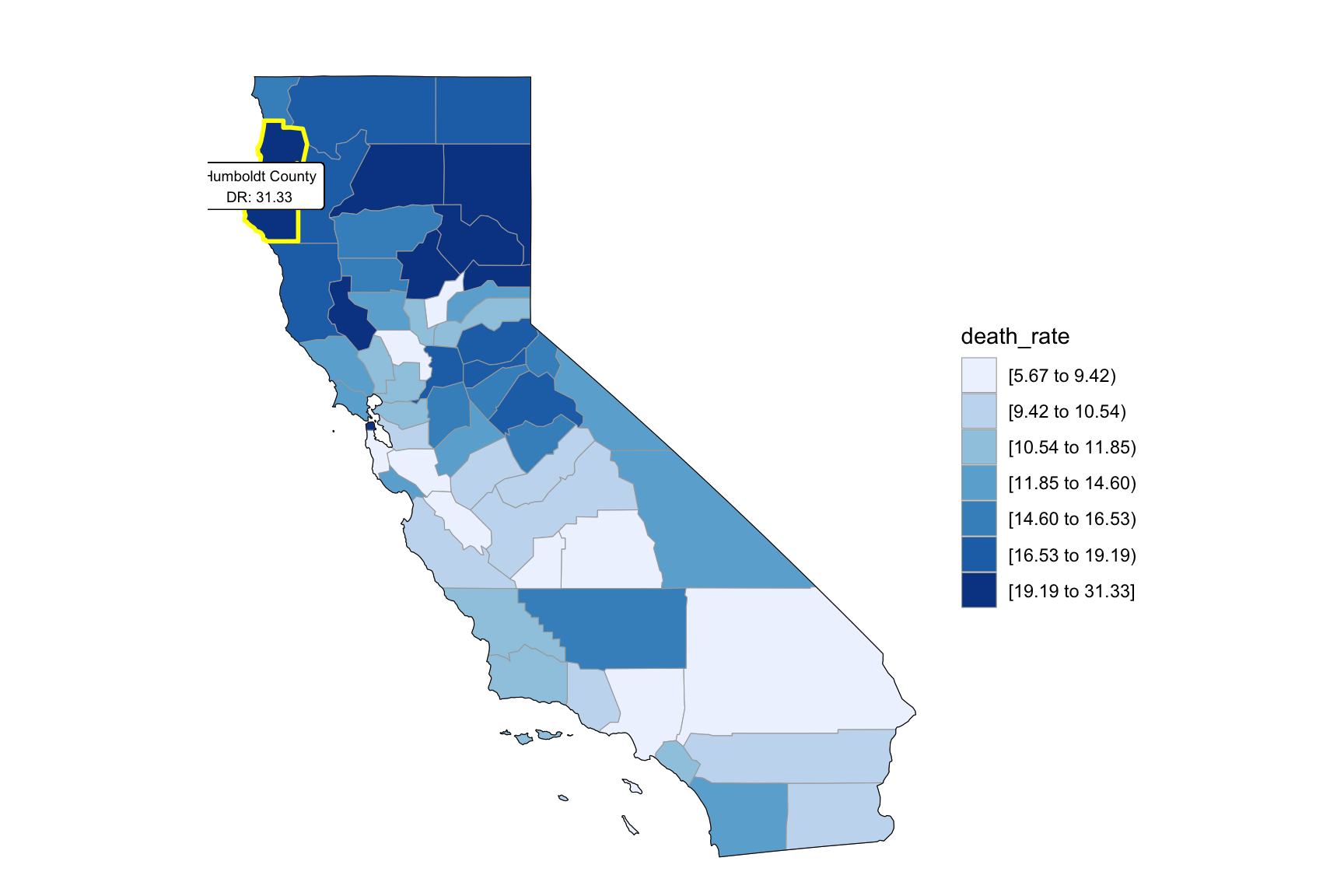
2013
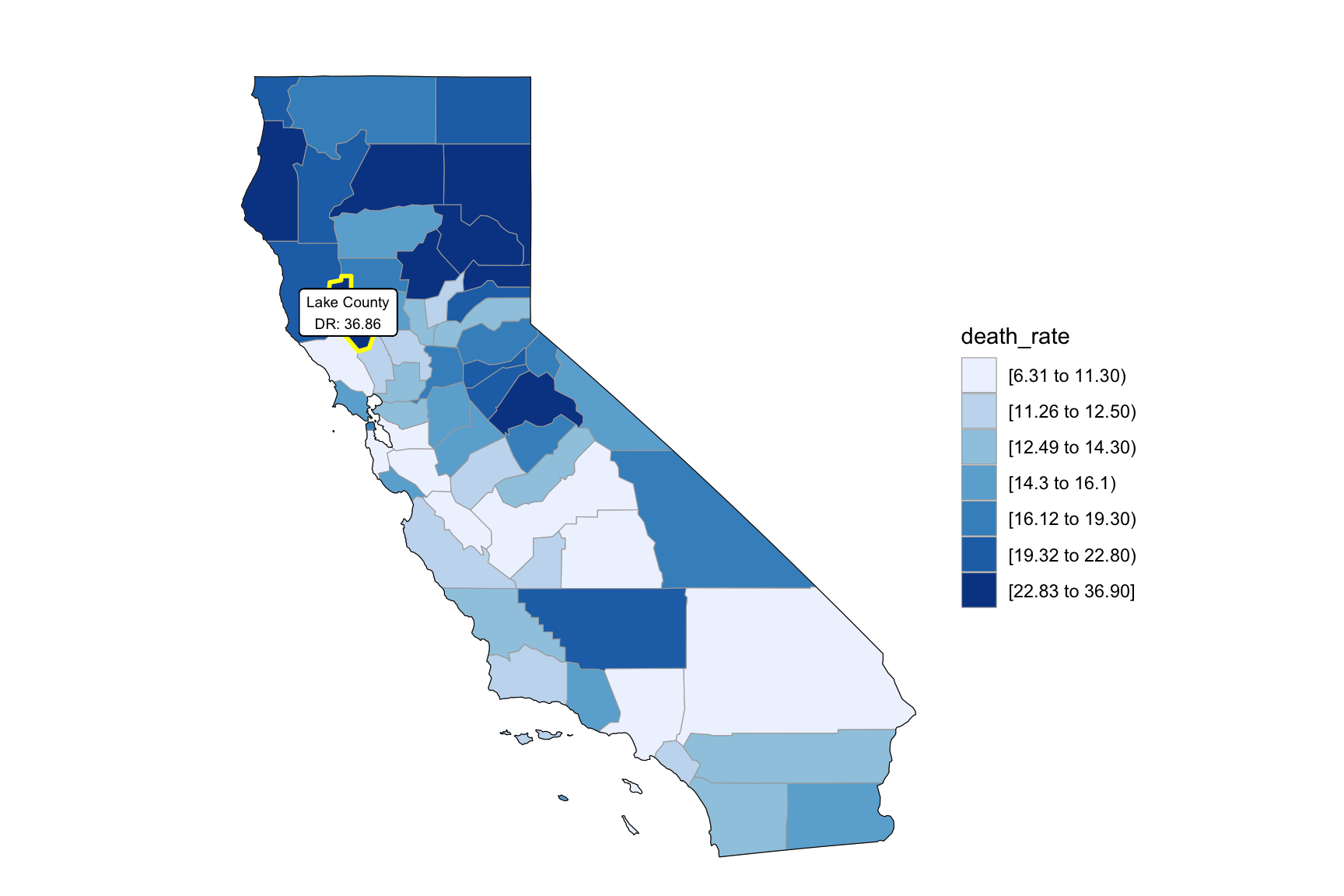
2018